










![]()
Introduction of multimedia codecs
|
4.6 MPEG Audio |
||||||||||||||||||||||||||||||
MPEG-1 supports mono, stereo and dual mono sounds at 32, 44.1, and 48 kHz sampling rate. The predefined bit rate is from 32 to 448 Kbps for Layer I, from 32 to 384 Kbps for Layer II and from 32 to 320 Kbps for Layer III. Specially, at bit rates from 64kb/s up to 192kb/s per channel, MPEG Audio Layer II can provide a sound quality that is competitive to any perceptual coding scheme using the same bit rate. It also provides a compatible multi-channel solution: the term "compatible" implies that MPEG2 Multi channel streams can replace any MPEG1 stereo stream in e.g. DVD and DVB systems while preserving compatibility with existing stereo decoders. Existing MPEG1 decoders are able to decode a stereo down-mix from the multi-channel stream they receive. [82] MPEG-2, or MPEG2 BC (backwards compatible), is backwards compatible for multi-channel extension to MPEG-1. It supports up to 5 main channels and a 'low frequent enhancement' (LFE) channel. Its bit rate is extended up to 1 Mbps; Furthermore, it is also an extension of MPEG-1 for lower sampling rates 16, 22.05, and 24 kHz for bit rates from 32 to 256 Kbps (Layer I) and from 8 to 160 Kbps (Layer II & Layer III). MPEG-2 AAC (Advanced Audio Coding) or MPEG NBC (Non-Backward Compatible audio) provides a very high-quality audio coding standard for 1 to 48 channels at sampling rates of 8 to 96 kHz, with multi-channel, multi-lingual, and multi-program capabilities. AAC works at bit rates from 8 Kbps for a monophonic speech signal up to in excess of 160 Kbps/channel for very-high-quality coding that permits multiple encode/decode cycles. Three profiles of AAC provide varying levels of complexity and scalability. [81] MPEG-4 supports coding and composition of natural and synthetic audio objects, scalability of the bitrate of an audio bit stream, scalability of encoder or decoder complexity, Structured Audio: A universal language for score-driven sound synthesis and TTSI, which is an interface for text-to-speech conversion systems. MPEG-7 will provide standardised descriptions and description schemes of audio structures and sound content and language to specify such descriptions and description schemes. [81] Compression factor of MPEG formats ranges from 2.7 to 24. With a compression rate of 6:1 (16 bits stereo sampled at 48 KHz is reduced to a 256 Kbps data stream) and under optimal listening conditions, expert listeners could not distinguish between coded and original audio clips. [83]
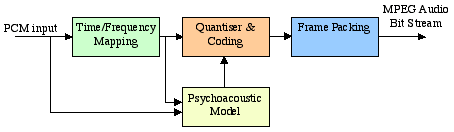
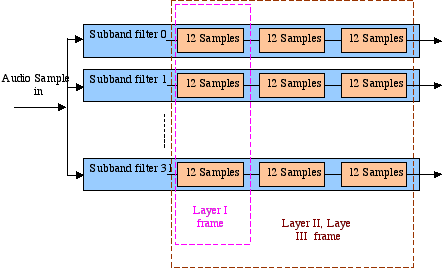
SBC encode: Sub-Band Coding (SBC) is a very popular and efficient audio method, which can encode any audio signal from any source. It is used for music recordings, movie soundtracks, etc. MPEG Audio is an example of SBC. When a lot of signal energy is present at one frequency, normal human ears cannot hear a signal at a lower energy at nearby frequencies. The louder frequency masks the softer frequencies and the louder frequency is called the masker. SBC uses this phenomenon to save signal bandwidth by throwing away information about frequencies, which are masked. This is a lossy encoding, but if the computation is done correctly, then the human ear can not hear the difference. [84] Here are the encoding procedures: [83] [84] (Figure 2-28 ) A time-frequency mapping (a filter bank, or FFT, or something else) is used to divide the input 48 kHz PCM signal into one that approximates the 32 critical sub-bands. The psycho-acoustic model checks both sub-bands and the original signal to determine masking thresholds using psycho-acoustic information. Each sample of the subband is quantised and encoded using these masking thresholds so as to keep the quantisation noise below the masking threshold. If the power in a subband is below the masking threshold, just ignore it. Otherwise, calculate the bits for the coefficient such that noise introduced by quantisation is below the masking effect. Then assemble all these quantised samples into frames to format bitstream. Figure 2-28 SBC encode[84] For decoding, the frames are unpacked and subband samples are decoded. Then, a frequency-time mapping translates them back into a PCM signal (Figure 2-29). Figure 2-29 SBC decode[84] MPEG Layers: MPEG defines 3 layers for audio. Their basic model is same, but the codec complexity increases with each layer. Each one is a self-contained SBC coder with its own time-frequency mapping, psycho-acoustic model, and quantiser. Layer 1 is the simplest, but gives the poorest compression. Layer 3 is the most complicated and difficult to compute, but gives the best compression. [84] Figure 2-30 Grouping of subband samples for Layer 1, 2, and 3[83] Each layer’s basic model is the same and is divided into frames that contain 384 samples (12 samples * 32 filtered sub-bands, Figure 2-30), but as already mentioned, the codec’s complexity increases with each layer. [83]
Effectiveness: In comparing the three layers, Layer 3 has the smallest stream bit rate and highest compression ratio, Layer 2’s bit rate is bigger and the compression ratio is not so good, whereas Layer 1 has the biggest bit rate and the smallest compression ratio. That’s way MP3 (MPEG layer 3) music is so popular on the web. Because of the complexity of the encoders, the sequence of theoretical delay, from shorter to longer in the various MPEG layers is Layer 1, Layer 2 and Layer 3. So, for the real-time communication, Layer 1 or layer 2 is probably more suitable. Because this encoding is lossy, the quality of the sound will be affected by the encoding bit depth. Experiments have shown that at a 64 Kbits encoding bit depth, Layer 3 provides a good qualitative reproduction but Layer 2 had some annoying interference. When using a 128 Kbits encoding bit depth, both Layer 3 and Layer 2 provided excellent effects. [83] The effectiveness of each layer is listed in Table 2-6. Table 2-6 Effectiveness of MPEG audio[83]
MPEG2 AAC (Advanced Audio Coding): MPEG-2 AAC or NBC (Non-Backward Compatible audio) is the consequent continuation of the coding method of MPEG Audio Layer 3. It supports high coding gain with great flexibility. This method is compatible for future developments in the audio sector with sampling frequencies between 8 kHz and 96 kHz and any number of channels between 1 and 48. It may just get half the bit rate without loss of subjective quality if compared to MPEG-2 Layer-2. MPEG2 AAC also offers a better compression ratio than layer-3. MPEG formal listening tests have demonstrated it is able to provide slightly better audio quality at 96 kb/s than layer-3 at 128 kb/s or layer-2 at 192 kb/s. The crucial differences between MPEG-2 AAC and its predecessor ISO/MPEG1 Layer 3 are shown as follows: [85]
|
||||||||||||||||||||||||||||||

![]()
Designed by Yong Qiu Liu.
Copyright © 2006 All rights reserved