










![]()
Introduction of multimedia codecs
|
4.5 G.723.1 Audio |
|
G.723.1, also called TrueSpeech 6.3/5.3, is a member in the TrueSpeech family of speech compression algorithms from DSP Group, Inc., and produces digital voice compression levels of 20:1 and 24:1 respectively (6.3 Kbps and 5.3 Kbps). It is the highest quality compression algorithm DSP Group offers. It is adopted by the International Telecommunications Union (ITU) as a recommendation of ITU-T, called G.732.1, to specifies a coded representation used for compressing the speech or other audio signal component of multi-media services at a very low bit rate over public telephone (POTS) networks as part of the H.324 family. It is also used for the ITU H.323 audio and video standard as the low bit rate speech technology recommendation [22]. G.732 or G.723.1 Sometimes people call G.723.1 as G.723. Actually in the past, no coder designated as G.723 has ever existed. It was later folded into G.726. The ITU changed the name of the currently adopted G.723 coder to G.723.1 in order to avoid confusion. Thus, there is no real distinction between G.723.1 and G.723 with reference to the currently adopted G.723.1 standard[23]. Bit rates supported The G.723.1 coder has two bit rates associated with it. These are 5.3 Kbps with the ACELP algorithm that has a good quality and additional flexibility to the system designer, and 6.3 Kbps with the MP-MLQ algorithm that has a better quality. Both rates are mandatory parts of the encoder and decoder. This codec enables voice communications through the Internet and other audio compression applications just like over a regular telephone[23]. Encoder/Decoder As the G.723.1 coder is designed to operate with a digital signal, the following steps are performed to convert the analogue signal to digital samples suitable for the encoder.
The processes used after decoding are similar and convert the digital samples back to an analogue signal.
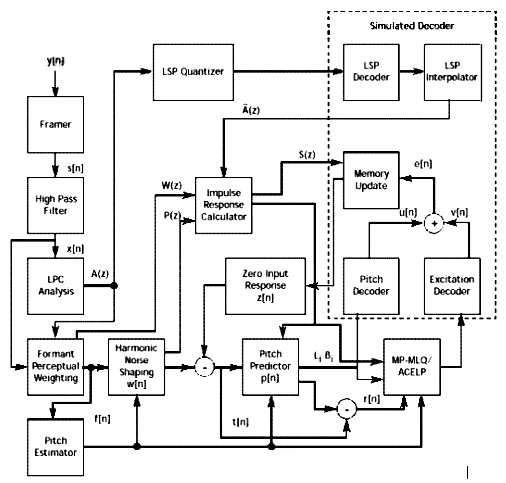
Figure 2-27 G.723.1 codec block diagram [19] The codec uses a linear prediction analysis-by-synthesis coding to minimise a perceptually weighted error signal. As shown in figure 6, some key processes used in the codec algorithm are described below.
Time delay: Using this codec, the total algorithmic delay is 37.5 ms, where 30 ms is the frame size and 7.5 ms is an additional look ahead time. In addition to this delay, there are processing delays for the implementation, transmission delays in the communication link and buffering delays of the multiplexing protocol[21]. Testing: Extensive tests were performed before TrueSpeech 6.3/5.3 was selected by the ITU as the G.723.1 standard. The tests included a variety of conditions such as situations with background noise, individuals speaking different languages, male and female talkers, multiple people talking simultaneously, etc. Handling lost packets, also known as frame erasure, was also tested to determine the algorithm’s robustness. This is especially important to enable high quality voice communications in an Internet environment. TrueSpeech 6.3/5.3’s outstanding performance has led it to be selected by the ITU as the recommendation G.723.1[20]. G.723.1 is an international standard currently in force as an international standard codec for voice on the Internet, with high compression ratio and very good audio quality. It has been used for POTS defined in the protocol stack H.324 and LAN and TCP/IP video conferencing defined in H.323[20]. |
![]()
Designed by Yong Qiu Liu.
Copyright © 2006 All rights reserved