G.728 is an ITU
(The International Telecommunications Union) standard that supplies
16 Kbps algorithm for telephone-bandwidth speech codec using LD-CELP
(Low-Delay Code-Excited Linear Prediction) method. It was designed
to provide speech quality which is equivalent to or better than
that of the G.726 32 Kbps ADPCM standard. Based on a standard
analysis-by-synthesis CELP
coding technique, the algorithm is designed to meet the needs
of low-delay high-quality speech coding. By using short excitation
vectors (5 samples, or 0.625 ms) and backward-adaptive linear
predictors, the algorithmic delay of the resulting coder is 0.625
ms. Then the overall delay is less than 2 ms. It can be used in
the environment of multiple speakers and background noise, and,
also, to handle non-speech signals. [49]
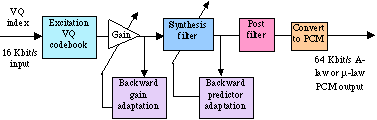
LD-CELP Codec:
LD-CELP is inherited
from CELP by implementing
its analysis-by-synthesis approach to code-book search and has
improved it by adding backward adaptation of predictors and gain
to achieve an algorithmic delay of 0.625 ms. LD-CELP only transmits
the index to the excitation codebook and updates the predictor
coefficients through LPC
analysis of previously quantised speech. It updates the excitation
gain by using the gain information which is embedded in the previously
quantised excitation. There are only five samples in the block
size for the excitation vector and gain adaptation. LPC is used
to update the perceptual weighting filter in the analysis of the
unquantised speech.[50]
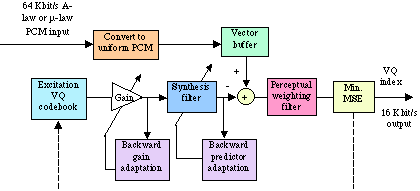
Uniform
PCM Converter:
Converting the A-law
or µ -law
PCM to uniform PCM.
Vector
Buffer: the uniform PCM signal is partitioned into
blocks of five-consecutive input signal samples to form a 5-dimensional
speech vector.
Adapter
for perceptual weighting filter: calculates the coefficients
of the perceptual weighting filter once every four speech vectors
based on linear prediction analysis (often referred to as LPC
analysis) of unquantised speech.
Perceptual
weighting filter: Converts the current input speech
vector to the weighted speech vector.
Synthesis
filter: The synthesis filter is updated by the backward
synthesis filter adapter. The synthesis filter is a 50-th order
all-pole filter that consists of a feedback loop with a 50-th
order LPC predictor in the feedback branch.
Backward
synthesis filter adapter: This
adapter updates the coefficients of the synthesis filter and takes
the quantised (synthesised) speech as input and produces a set
of synthesis filter coefficients as output.
Backward
vector gain adapter: For every vector time index,
the adapter updates the excitation gain which is a scaling factor
used to scale the selected excitation. This adapter takes the
gain-scaled excitation vector as its input, and produces an excitation
gain as its output.
Excitation
VQ codebook: Supplies a 1024 candidate code book of
vectors for each input block.
Min. MSE
(Mean-Squared Error) measure:
From the resulting 1024 candidate quantised signal vectors, the
encoder identifies the one that minimises a frequency-weighted
Mean-Squared Error measure with respect to the input signal vector.
The 10-bit code-book index of the corresponding best code-book
vector (or "codevector"), which gives rise to that best
candidate quantised signal vector, is transmitted to the decoder.
Then the best codevector from minimum
MSE measure is then passed through the gain scaling unit and the
synthesis filter to establish the correct filter memory in preparation
for the encoding of the next signal vector. The synthesis filter
coefficients and the gain are updated periodically in a backward
adaptive manner based on the previously quantised signal and gain-scaled
excitation.
Excitation VQ
codebook: This block
contains an excitation VQ codebook (including shape and gain codebooks).
It uses the received best codebook index to extract the best code
vector selected in the LD-CELP encoder.
Gain scaling
unit: Computing the scaled excitation vector by multiplying
each component by the gain.
Synthesis
filter: Filtering the
scaled excitation vector to produce the decoded speech vector.
Decoder:
The decoding operation is also performed on a block-by-block
basis. Upon receiving each 10-bit index, the decoder performs
a table look-up to extract the corresponding codevector from the
excitation codebook. The extracted codevector is then passed through
a gain scaling unit and a synthesis filter to produce the current
decoded signal vector. The synthesis filter coefficients and the
gain are then updated in the same way as in the encoder. The decoded
signal vector is then passed through an adaptive post-filter to
enhance the perceptual quality. The post-filter coefficients are
updated periodically using the information available at the decoder.
The five samples of the post-filter signal vector are next converted
to five A-law or
µ -law PCM
output samples.